Macro view of Maps in Golang
Table of Contents
About
This article will focus on explaining macro view of maps in Go and why are they an unsorted collections. You should have atleat a basic knowledge of what are maps in Golang. If you don’t know don’t worry I will try to explain it as clearly as I can.
What are maps in Golang?
A map is a builtin type in Go that is used to store key-value pairs. Let’s take the example of a startup with a few employees. For simplicity, let’s assume that the first name of all these employees is unique. We are looking for a data structure to store the salary of each employee. A map will be a perfect fit for this use case. The name of the employee can be the key and the salary can be the value. Maps are similar to dictionaries in other languages such as Python.
To learn more about map, refer to golang website.
Introduction
There are lots of posts that talk about the internals of slices, but when it comes to maps, we are left in the dark. I was wondering why and then I found the code for maps and it all made sense. At least for me, this code is complicated. That being said, I think we can create a macro view of how maps are structured and grow. This should explain why they are unordered, efficient and fast.
Creating and Using Maps
Let’s look at how we can use a map literal to create a map and store a few values:
// Create an empty map with a key and value of type string.
employee := map[string]string{}
// Add a few keys/value pairs to the map.
employee["name"] = "knrt10"
employee["age"] = "23"
employee["tag"] = "Cloud Infrastructure Engineer"
employee["location"] = "India"
When we add values to a map, we always specify a key that is associated with the value. This key is used to find this value again without the need to iterate through the entire collection:
fmt.Printf("Value: %s", employee["name"])
If we do iterate through the map, we will not necessarily get the keys back in the same order. In fact, every time you run the code, the order could change:
employee := map[string]string{}
employee["name"] = "knrt10"
employee["age"] = "23"
employee["tag"] = "Cloud Infrastructure Engineer"
employee["location"] = "India"
for key, value := range employee {
fmt.Printf("%s:%s, ", key, value)
}
# Output:
location:India, name:knrt10, age:23, tag:Cloud Infrastructure Engineer,
name:knrt10, age:23, tag:Cloud Infrastructure Engineer, location:India,
Now that we know how to create, set key/value pairs and iterate over a map, we can peek under the hood.
Macro view
Maps in Go are implemented as a hash table. If you need to learn what a hash table is, there are lots of articles and posts about the subject. You can learn about Hash table on Wikipedia.
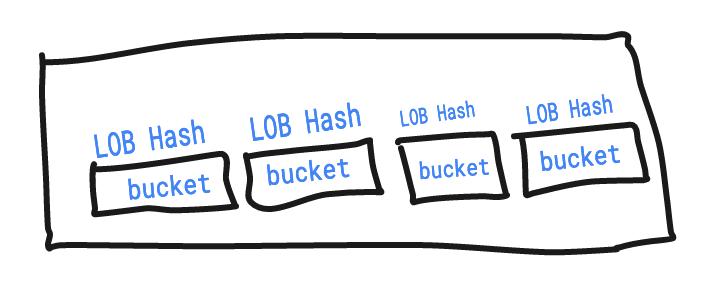
A map is just a hash table. The data is arranged into an array of buckets. The number of buckets is always equal to a power of 2. Each bucket contains up to 8 key/value pairs.
When a map operation is performed, such as (employee["name"] = "knrt10"), a hash key is generated against the key that is specified. In this case the string “name” is used to generate the hash key. The low order bits (LOB) of the generated hash key is used to select a bucket. If more than 8 keys hash to a bucket, it chains on extra buckets.
The low-order bits of the hash are used to select a bucket. Each bucket contains a few high-order bits of each hash to distinguish the entries within a single bucket.
Once a bucket is selected, the key/value pair needs to be stored, removed or looked up, depending on the type of operation. If we look inside any bucket, we will find two data structures. First, there is an array with the top 8 high order bits (HOB) from the same hash key that was used to select the bucket. This array distinguishes each individual key/value pair stored in the respective bucket. Second, there is an array of bytes that store the key/value pairs. The byte array packs all the keys and then all the values together for the respective bucket.
When we are iterating through a map, the iterator walks through the array of buckets and then return the key/value pairs in the order they are laid out in the byte array. This is why maps are unsorted collections. The hash keys determines the walk order of the map because they determine which buckets each key/value pair will end up in.
The 1 byte value in this map would result in 7 extra bytes of padding per key/value pair. By packing the key/value pairs as key/key/value/value, the padding only has to be appended to the end of the byte array and not in between. Eliminating the padding bytes saves the bucket and the map a good amount of memory. I will explain about alignment boundaries is some other article
A bucket is configured to store only 8 key/value pairs. If a ninth key needs to be added to a bucket that is full, an overflow bucket is created and reference from inside the respective bucket.
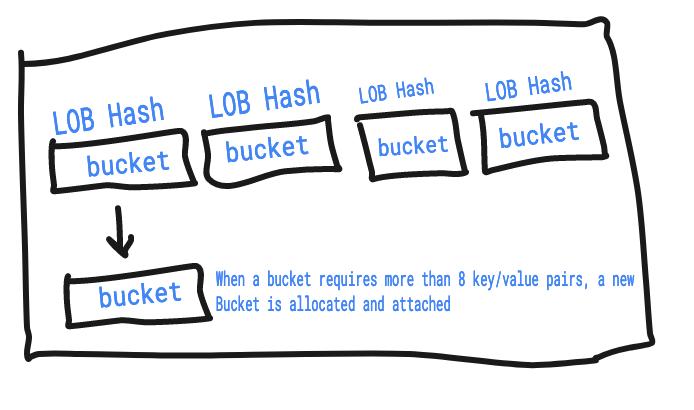
How Maps Grow
As we continue to add or remove key/value pairs from the map, the efficiency of the map lookups begin to deteriorate. The load threshold values that determine when to grow the hash table are based on these four factors:
% overflow : Percentage of buckets which have an overflow bucket
bytes/entry : Number of overhead bytes used per key/value pair
hitprobe : Number of entries that need to be checked when looking up a present key
missprobe : Number of entries that need to be checked when looking up an absent key
Some stats for different loads for (64-bit, 8 byte keys and elems)
// loadFactor %overflow bytes/entry hitprobe missprobe
// 4.00 2.13 20.77 3.00 4.00
// 4.50 4.05 17.30 3.25 4.50
// 5.00 6.85 14.77 3.50 5.00
// 5.50 10.55 12.94 3.75 5.50
// 6.00 15.27 11.67 4.00 6.00
// 6.50 20.90 10.79 4.25 6.50
// 7.00 27.14 10.15 4.50 7.00
// 7.50 34.03 9.73 4.75 7.50
// 8.00 41.10 9.40 5.00 8.00
Growing the hash table starts with assigning a pointer called the “old bucket” pointer to the current bucket array. Then a new bucket array is allocated to hold twice the number of existing buckets. This could result in large allocations, but the memory is not initialized so the allocation is fast.
Important: Once the memory for the new bucket array is available, the key/value pairs from the old bucket array can be moved or “evacuated” to the new bucket array. Evacuations happen as key/value pairs are added or removed from the map. The key/value pairs that are together in an old bucket could be moved to different buckets inside the new bucket array. The evacuation algorithm attempts to distribute the key/value pairs evenly across the new bucket array.
Conclusion
This is just a macro view of how maps are structured and grown. You can look into the the code to undestand more how it works. It does show that if you know how many keys you need ahead of time, it is best to allocated that space during initialization.
Did you find this page helpful? Consider sharing it 🙌
Kautilya Tripathi
Software Engineer 2
Certified Kubernetes Security Specialist (CKS) | Certified Kubernetes Administrator (CKA) | Distributed Systems | Systems Programming | OSS ❤️