Anatomy of Structs in Golang
Table of Contents
About
In the previous post we learnt about Macro view of Maps in Golang, but in this post we will learn more about Structs. Structs are building blocks of a Go application and anyone writing modular Go code will find themselves using it a lot. This spurred me to take a deep dive into exactly what a struct is, how they are represented in memory, and how to get the most out of structs.
What are structs in Golang?
A struct is a user-defined type that represents a collection of fields. It can be used in places where it makes sense to group the data into a single unit rather than having each of them as separate values.
In simple language, an employee has a firstName, lastName and age. It makes sense to group these three properties into a single struct named Employee.
type Employee struct {
firstName string
lastName string
age int
}
Declaring a struct
type Employee struct {
firstName string
lastName string
age int
}
The above snippet declares a struct type Employee with fields firstName, lastName and age. The above Employee struct is called a named struct because it creates a new data type named Employee using which Employee structs can be created.
This struct can also be made more compact by declaring fields that belong to the same type in a single line followed by the type name. In the above struct firstName and lastName belong to the same type string and hence the struct can be rewritten as
type Employee struct {
firstName, lastName string
age int
}
Although the above syntax saves a few lines of code, it doesn’t make the field declarations explicit. Please refrain from using the above syntax.
Using a Struct
package main
import (
"fmt"
)
type Employee struct {
firstName string
lastName string
age int
salary int
}
func main() {
//creating struct specifying field names.
emp1 := Employee{
firstName: "Sam",
age: 25,
salary: 500,
lastName: "Anderson",
}
//creating struct without specifying field names.
emp2 := Employee{"Thomas", "Paul", 29, 800}
fmt.Println("Employee 1", emp1)
fmt.Println("Employee 2", emp2)
}
In the above code we first define a struct Employee with the given fields. Then inside the main function we declare a variable emp1 of type Employee with it’s corresponding values. Any fields omitted from when instantiating a struct will take on the zero value of that field’s type. E.g. if age was omitted when creating a user the default value is 0.
Similarly we define a variable emp2 with diffrent values and then print both the structs. The above program outputs
Employee 1 {Sam Anderson 25 500}
Employee 2 {Thomas Paul 29 800}
This was the basics of structs, to learn more about struct follow the tour of go. This guide focuses more on memory representation of struct so we will now learn about it.
Memory Representation
When it comes to memory allocation for structs, they are always allocated contiguous, byte-aligned blocks of memory, and fields are allocated and stored in the order that they are defined.
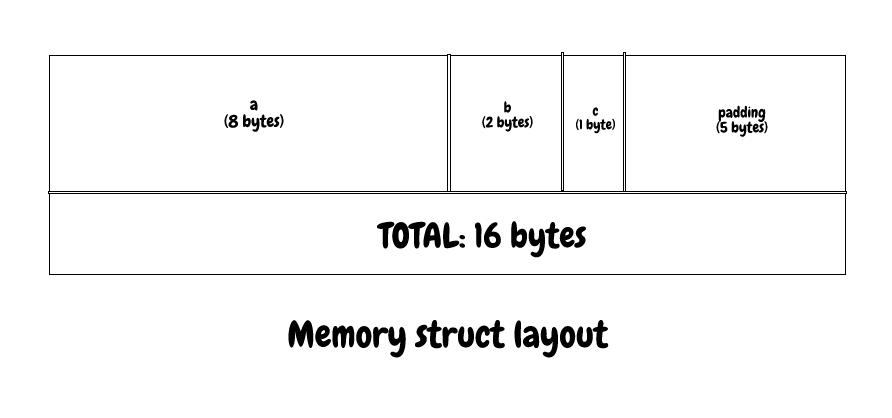
The concept of byte-alignment in this context means that the contiguous blocks of memory are aligned at offsets equal to the platforms word size (4 bytes on a 32-bit, 8 bytes on a 64-bit system). Consider the following example of a struct where there are three fields each of varying sizes, on a 64-bit environment blocks of memory will be aligned at 8 byte offsets.
This results in the first block of 8 bytes being fully occupied by a (8 bytes). The next block of memory (offset by 8 bytes from the starting memory address of the struct) has its first 2 bytes occupied by b, the next 1 byte occupied by c then the remaining 5 bytes are empty pad bytes.
package main
import (
"fmt"
"unsafe"
)
type MemoryTaken struct {
a int // 8 byte
b int16 // 2 bytes
c bool // 1 bytes
}
func main() {
fmt.Printf("Sizeof MemoryTaken: %d\n", unsafe.Sizeof(MemoryTaken{}))
}
When you run the above program you will get the following output:
Sizeof MemoryTaken: 16
Let us see the memory struct layout for the above struct MemoryTaken
Memory Optimisation
Considering how memory is allocated for structs as seen in the previous section, depending on the order that fields are defined in a struct it can be rather inefficient due to the number of pad bytes required. It is possible to optimise the memory utilisation of a struct however, by defining the fields in a deliberate order to maximise the use of each block of memory, reducing the need for redundant pad bytes.
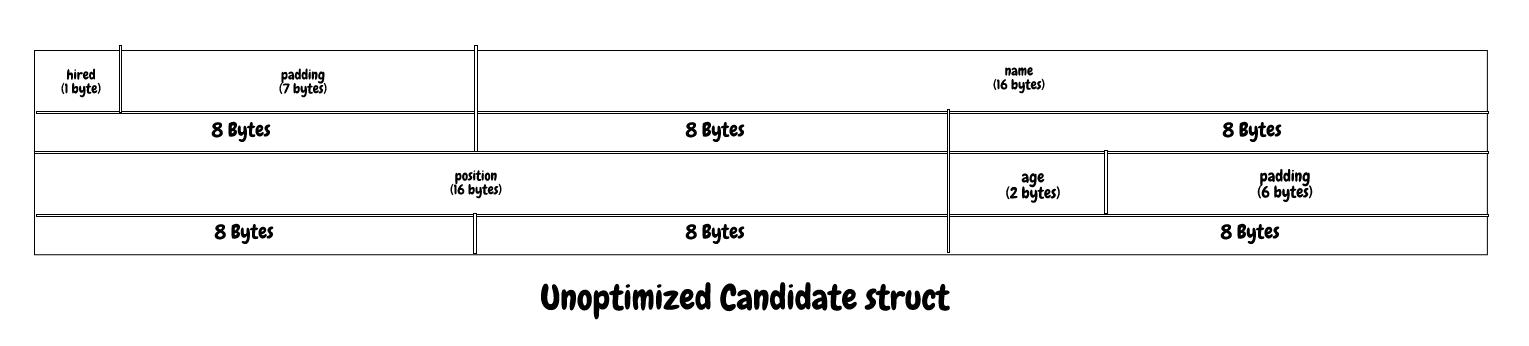
The following example there is a struct Canditate representing a candidate for a company. In the first iteration, before taking steps to optimise its memory utilisation the total memory of the combined fields totals 35 bytes, however, the total struct size equates to 48 bytes due to pad bytes.
package main
import (
"fmt"
"unsafe"
)
type Canditate struct {
hired bool // 1 byte
name string // 16 Bytes
position string // 16 Bytes
age int16 // 2 bytes
// 35 bytes total, 13 bytes padding
}
func main() {
fmt.Printf("Sizeof Unoptimized Canditate struct: %d\n", unsafe.Sizeof(Canditate{}))
}
When you run the above program you will get the following output:
Sizeof Unoptimized Canditate struct: 48
Now we will see the memory representation for the struct Canditate above:
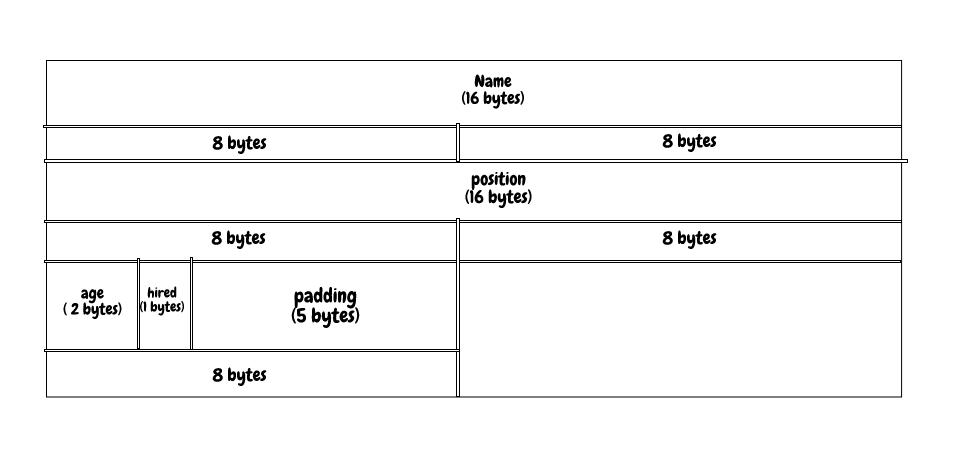
Now, if the struct fields are re-arranged to minimise padding bytes, the resulting struct size is only 40 bytes.
package main
import (
"fmt"
"unsafe"
)
type Canditate struct {
name string // 16 Bytes
position string // 16 Bytes
age int16 // 2 bytes
hired bool // 1 byte
// 35 bytes total, 5 bytes padding
}
func main() {
fmt.Printf("Sizeof Optimized Canditate struct: %d\n", unsafe.Sizeof(Canditate{}))
}
When you run the above program you will get the following output:
Sizeof Optimized Canditate struct: 40
Conclusion
In modern systems where memory constraints are not typically an issue, the benefit gained from micro-optimisations like this, reclaiming 8 bytes of memory is not enormous. However, the ability to understand at this level, how a struct is allocated memory, and how to, if required apply such optimisations is invaluable.
Did you find this page helpful? Consider sharing it 🙌
Kautilya Tripathi
Software Engineer 2
Certified Kubernetes Security Specialist (CKS) | Certified Kubernetes Administrator (CKA) | Distributed Systems | Systems Programming | OSS ❤️